유클리디안 거리, 맨해튼 거리, 의사결정 트리
● 거리를 구할 때, '유클리디안 거리' 말고도 다른 수학적 방법이 있습니다. '맨해튼 거리'라고 불리죠.
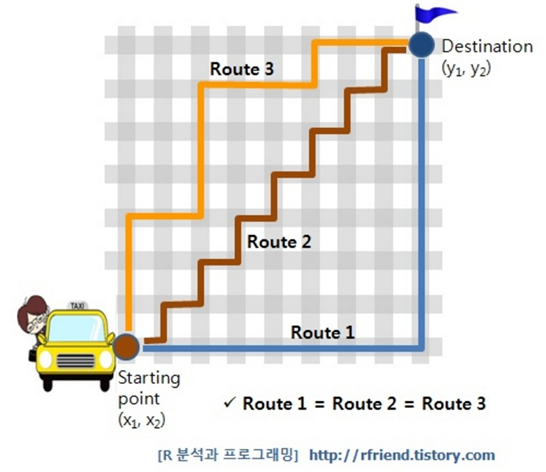
- 군대 훈련소에서 남자들은 직각 보행을 합니다.
- 맨해튼 시내에 빌딩이 많아 격자 모양의 길이 많아 생겨난 말로 x축, Y축을 따라 간 거리입니다.
● 주의할 점이 있습니다. 좌표상의 한 점으로 나타내려면 데이터의 변수(특성)에 따른 값을 숫자로 나타내야겠죠? 이 숫자 데이터의 Scale(범위)은 저마다 다릅니다. 그러므로 0~1 사이의 값으로 변환시키는 정규화 과정을 꼭 거쳐야 합니다.
● KNN은 담백하고, 빠릅니다. 데이터를 수치로 표현할 수 있다면 성능이 우수하므로 사용을 고려해볼 만합니다..
● 반면 KNN은 K의 개수 설정에 따라 결과가 달라지므로, K의 선택이 매우 중요합니다. 데이터가 많으면, 분류가 자연히 느려지는 단점도 존재합니다. KNN을 쓰려면 수치 형태의 데이터로 변환하는 단계가 꼭 필요하고요..
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
● 의사결정 트리의 초청장을 받았습니다. 의사결정 트리를 쉽게 이해할 수 없을까요?
● 의사결정 트리는 스무고개의 원리입니다. 질문에 대해 예/아니오로 대답하며 원하는 대상을 분류하거나 예측할 수 있습니다.

● 위와 같이 특정 질문에 따라 데이터를 구분하는 모델을 의사결정 트리 모델이라고 합니다. 나무를 뒤집어 놓은 모양과 매우 비슷하군요.
● 의사결정 트리의 핵심은 무엇일까요? 첫 번째는 질문이고, 두 번째는 질문의 순서입니다.
● 첫번째, 질문이라 함은 데이터를 가장 잘 나눌 수 있는 기준을 뜻합니다.
- 머신러닝에서 중요한 점은 결정적인 특성을 추출(Feature Extraction)해내는 것입니다.
- 이 특성을 유용하게 추출하거나 뽑아내기 위해 특성 공학(Feature Engineering)이 발달했습니다.
- 머신러닝 알고리즘인 의사결정 트리도 마찬가지입니다. 결정적인 특성을 담은 의미 있는 질문을 하는 것이 중요합니다.
● 두번째, 질문의 순서입니다. 중요한 질문을 처음에 하는 것이 좋을까요? 아니면 나중에 하는 것이 좋을까요?
- 의미 있는 질문은 먼저 하는 것이 중요합니다.
- 답에 관해 많은 정보를 가진 질문을 먼저 하게 되면 정답이 아닌 특성을 가진 데이터를 단번에 많이 제외시킬 수 있게 되고, 그만큼 정답에 빠르고 쉽게 접근할 수 있게 되기 때문입니다.
● 아하, 다시 한번 정리해봅시다. 의사결정 트리는 할 수 있는 질문들 중에서 데이터를 가장 잘 나누는 의미 있는 질문을 찾습니다. 또, 그 와중에 의미있는 질문을 먼저 하도록 알고리즘이 설계되어 있는 거군요.
● 그럼 데이터를 가장 잘 나누는 의미있는 질문을 어떻게 찾을 수 있을까요? 그것은 학습을 통해서입니다.
- 훈련 데이터로 학습을 하게 되면 데이터의 속성을 반영한 질문들을 통해 데이터를 잘 분류하고 예측해내는 의사결정트리 모델을 얻게 됩니다.
● 그럼 질문들의 순서는 어떻게 고려할 수 있는 걸까요? 즉, 데이터를 가장 잘 나눠주는 가장 의미있는 질문(=상위에 배치해야 하는 질문)은 어떻게 찾을 수 있는 것일까요?
- 이를 설명하기 위해 조금 복잡하지만 ‘불순도’와 ‘엔트로피’, ‘정보획득’ 등의 개념에 대해 가볍게 살펴볼 필요가 있습니다.
● 다음 시간에는 이 개념들을 다뤄보고, 의사결정 트리를 전체적으로 조망해보도록 하죠!
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
● 불순도는 어떤 공간에 서로 다른 데이터가 얼마나 섞여 있는지를 뜻합니다.
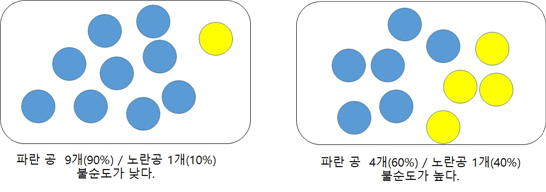
● 엔트로피는 불순도를 숫자로 나타내기 위해 열역학의 개념을 빌려온 것입니다. 엔트로피가 1이면 불순도가 가장 높은 경우이고, 엔트로피가 0이면 불순도가 낮은 순수한 상태입니다.
- 의사결정 트리는 불순도를 가장 작게 하는 방향으로 학습을 진행합니다.
● 정보획득은 부모 노드의 엔트로피 값에서 자식 노드의 엔트로피 값을 뺀 값입니다.
- 즉, 정보획득량이 가장 큰 질문이 좋은 질문이고, 이 질문을 상위에 배치합니다.
● 기억합시다. 의사결정트리는 정보획득을 최대화하는 방향으로 학습이 진행됩니다.
● 이렇듯 의사결정트리는 엔트로피라는 개념을 사용해서 각 질문들에 대한 정보획득량을 구하고, 정보획득이 높은 질문을 먼저 하도록 하여 데이터를 분리하는 과정을 반복함으로써, 의사결정 트리를 만들어갑니다.
● 이상 AI가 의사결정트리를 만드는 원리를 수식 없이 이해해봤습니다.
● 다음 시간에는 의사결정 트리도 마무리될 듯합니다.. 어제와는 새로운 좋은 날 되십시오.
'인공지능' 카테고리의 다른 글
| 9번째 인공지능 - 배깅(Bagging), 배깅피쳐(Bagging Feature) (0) | 2022.08.16 |
|---|---|
| 8번째 인공지능 - 의사결정트리 (0) | 2022.08.16 |
| 6번째 인공지능 - SVM, 커널, 커널트릭, K-최근접 이웃(KNN) 알고리즘 (0) | 2022.08.16 |
| 5번째 인공지능 - 신경 세포 뉴런, SVM (0) | 2022.08.16 |
| 4번째 인공지능 - 기울기 소실 문제 (0) | 2022.08.16 |




댓글